
一、RSS阅读器的实现
RSS Reader的实现并不像它看上去那么复杂。当初在决定写这个作为Lisp练习时,甚至觉得 没有多少内容可做。其简单程度甚至用不了你启动一个慢速IDE的时间:D。对Lisp无兴趣的 TX只需要读完这一节即可,
什么是RSS阅读器?
RSS在实现上,可以说是XML的又一次扩张式的应用。因为RSS最重要的东西就是一个XML文件 。RSS主要用于Web中的内容同步。例如我们写的博客,门户网站的新闻,都是内容。Web服 务器将这些内容组织成XML,然后我们通过一个客户端来解析这些XML,就可以在不用直接访 问网站的情况下获取信息: 
RSS阅读器就是这样一个从Web服务器通过RSS(表现形式为XML)来获取信息内容的工具。它 可以被实现为一个独立的客户端程序,也可以实现为像Google Reader这种网页形式。后者 其核心功能其实是Google服务器在做,取得信息后再发给用户。
RSS文件
上已提及,RSS的实现其实就是个XML文件。这个XML文件格式非常简单,例如:
<?xml version="1.0"?>
<rss version="2.0">
<channel>
<title>Liftoff News</title>
<link>http://liftoff.msfc.nasa.gov/</link>
<description>Liftoff to Space Exploration.</description>
<item>
<title>Star City</title>
<link>http://liftoff.msfc.nasa.gov/news/2003/news-starcity.asp</link>
<description>Oh no, you wrote another blog!</description>
</item>
</channel>
</rss>我们身边到处都是RSS文件,例如 http://www.cppblog.com/rss.aspx 。RSS文件的框架大 致为:
1
2
3
4
5
6
7
8
9
<rss>
<channel>
<item>
</item>
<item>
</item>
...
</channel>
</rss>
对,其框架就是这样,一个channel节点,其下若干个item节点。举例来说, CPPBLOG首页就 是一个channel,该channel下有若干原创文章,每篇文章就是一个item。 无论是channel ,还是item,都会有很多属性,例如title/description/link,有些属性是RSS规范里要求 必须有的,有的是可选的。
交互过程
那么,服务器和客户端是如何交互的呢?首先,服务器上的程序针对其某个页面,生成对应 的RSS文件。这个RSS文件基本上是有固定的URL的。客户端每次获取内容时,就从这个固定 的URL获取这个RSS文件。客户端获取到这个RSS文件后,解析之,再呈现给用户。这就是整 个过程。这个过程中客户端与服务器的交互,全部是正常的HTTP请求。
而RSS阅读器,如果做得足够简单,则只需要从指定的地方获取到RSS文件,然后解析这个 XML文件,然后以相对友好的形式显示即可。
扩展
虽然RSS阅读器在核心功能上很简单,但是作为一个可以使用的工具,依然有很多功能点需 要实现。基本功能包括:
- 记录用户关注的RSS
- 缓存某个RSS过去一段时间更新的内容
- 对HTTP回应的处理,最重要的就是重定向处理
我们还可以做很多扩展,例如Google Reader之类的在线RSS阅读器。这些阅读器的RSS抓取 功能做在服务器端,它们除了上面提到的基础功能外,还会包含内容分类,给内容打一些 标签,分析用户的订阅习惯然后推荐类似的内容等等。
二、Lisp实现
本节描述在Lisp中实现上文的内容。主要包括: 通过HTTP请求获取到RSS文件、解析RSS文件 。
获取RSS文件
Lisp虽然历史悠久,但其扩展库标准却做得很拙劣。偏应用级的扩展库要么由编译器实现提 供,要么就得自己在网上找。一方面使用者希望库使用起来方便,另一方面库开发者在跨编 译器实现方面也头疼不已。所幸现在有了quick lisp,安装第三方库就像Ubuntu里安装软件 一样简单(大部分)。
socket支持就是面临的第一个问题。不过我这里并不考虑跨编译器实现的问题,直接使用 SBCL里的socket接口。
要获取RSS文件,只需要连接Web服务器,发起HTTP的GET请求即可。当然,建立TCP连接,组 建HTTP请求包,就不是这里的讨论了。我们还是拿CPPBLOG首页的RSS为例,该RSS的URL为:
1
http://www.cppblog.com/rss.aspx
拆分一下,得到host为www.cppblog.com(即我们要connect的地址),rss的uri为 /rss.aspx(即HTTP请求里的文件URI),于是建立HTTP请求包:
1
2
GET /rss.aspx HTTP/1.0
Host: www.cppblog.com
关于HTTP请求的一些基础知识,可以参考我很早前写的一篇博客:<实现自己的http服务器>。 正常情况下,Web服务器就会返回RSS的文件内容。然后我们就可以继续解析。
解析RSS
RSS本身是一个XML格式的文件。之前连接Web服务器发起HTTP请求没有用到第三方库,但是 解析XML文件不是几十来行代码能搞定的事情,所以这里需要选用一个第三方库。
我用的是s-xml,这个库在我之前的 关于Lisp的文章 中提到过。s-xml与我之前在C++ 领域见到的XML解析库最大的不同点在于,它提供的API是基于事件模式的。意思是说,你不 要去查询某个element的值是多少,当我解析到的时候会告诉你。事件模式的编程方式自然 离不开回调函数:
(s-xml:start-parse-xml
stream
(make-instance 's-xml:xml-parser-state
:new-element-hook #'decode-rss-new-element
:finish-element-hook #'decode-rss-finish-element
:text-hook #'decode-rss-text)))与s-xml交互的也就是上面代码里提到的三个函数:new-element-hook, finish-element-hook , text-hook。这种类型的接口导致解析代码大量减少,但不利于理解。我们要在整个解析 过程中传递数据,需要通过与s-xml交互的函数参数(当然不会蠢到去用全局变量)。
解析过程中通过往函数参数指定的对象身上塞数据完成,整个解析实现也就几十行代码。 文章尾可下载代码看看。
显示出来
通过上面两步,我们得到了RSS文件、解析出了具体内容,最后一步就是呈现出来看看。RSS 文件里每个Item都是一篇文章(新闻之类),这个文章内容可直接包含HTML标记,说白了, 这些内容就是直接的HTML内容。要显示这些内容,最简单的方法就是把一个RSS转换成一种 简单的HTML文件,以供阅读。
这里就涉及到HTML generator,几乎所有的Lisper都会写一个HTML产生器(库)(虽然目前 我还没写)。这种库的作用就是方便地输出HTML文件。
Lisp相对于其他语言很大的一个特点,或者说是优点,就是其语言本身的扩展能力。这种扩 展不是简单的添加几个函数,也不是类,而是提供一些就像语言本身提供的特殊操作符一样 的东西。而HTML generator正是这种东西大放异彩的地方。这种感觉有点像在C++中通过模 板造出各种增强语言特性的东西一样(例如boost/loki)。
因为我这里只是输出简单的HTML文件,何况我对HTML的标记了解的也不多,也懒得再花经历 。所以我暂时也就将就了些土方法:
(with-output-to-string (stream)
(let ((channel (rss-channel rss))) ;取出channel对象
(format stream "<html><head><title>~a</title></head>"
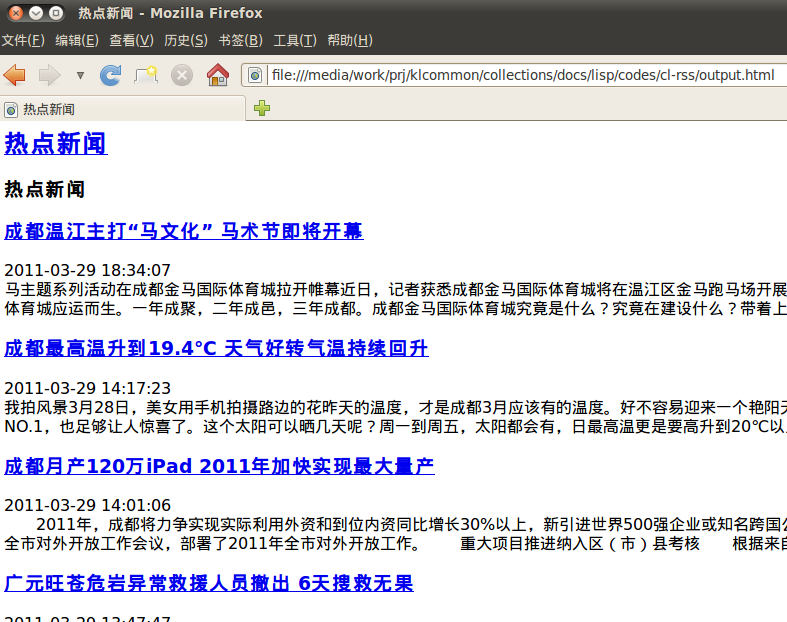
(get-property channel :|title|)) ;取出channel的title最后组合一些接口,即可将整个过程联系起来,导出html文件:
(cl-rss-test:test-rss-http :uri "/news/newshot/hotnewsrss.xml"
:host "cd.qq.com")然后在浏览器里查看,如图:
其他
当一些代码可以工作起来的时候,就可以着手测试这批代码。然后我就用这个工具测试我 Google Reader里订阅的一些RSS。最大的问题,就是关于HTTP重定向的问题。
当服务器返回301或者302的错误信息时(HTTP回应),就标示请求的URI被移动到了其他地 方,客户端需要访问新的地址。这个其实查查 HTTP的规范 就可以轻易解决。重定向时, 新的URI被指定在Response Header里的Location域,取出来发起第二次请求即可。
参考文档
- HTTP规范: http://www.w3.org/Protocols/rfc2616/rfc2616.html
- RSS2.0规范: http://feed2.w3.org/docs/rss2.html
;;EOF;;