
zookeeper中节点数量理论上仅受限于内存,但一个节点下的子节点数量受限于request/response 1M数据 (size of data / number of znodes)
zookeeper的watch机制用于数据变更时zookeeper的主动通知。watch可以被附加到每一个节点上,那么如果一个应用有10W个节点,那zookeeper中就可能有10W个watch(甚至更多)。每一次在zookeeper完成改写节点的操作时就会检测是否有对应的watch,有的话则会通知到watch。Zookeeper-Watcher机制与异步调用原理
本文将关注以下内容:
- zookeeper的性能是否会受节点数量的影响
- zookeeper的性能是否会受watch数量的影响
测试方法
在3台机器上分别部署一个zookeeper,版本为3.4.3,机器配置:
1
2
3
4
5
6
7
Intel(R) Xeon(R) CPU E5-2430 0 @ 2.20GHz
16G
java version "1.6.0_32"
Java(TM) SE Runtime Environment (build 1.6.0_32-b05)
OpenJDK (Taobao) 64-Bit Server VM (build 20.0-b12-internal, mixed mode)
大部分实验JVM堆大小使用默认,也就是1/4 RAM:
1
java -XX:+PrintFlagsFinal -version | grep HeapSize
测试客户端使用zk-smoketest,针对watch的测试则是我自己写的。基于zk-smoketest我写了些脚本可以自动跑数据并提取结果,相关脚本可以在这里找到:https://github.com/kevinlynx/zk-benchmark
测试结果
节点数对读写性能的影响
测试最大10W个节点,度量1秒内操作数(ops):
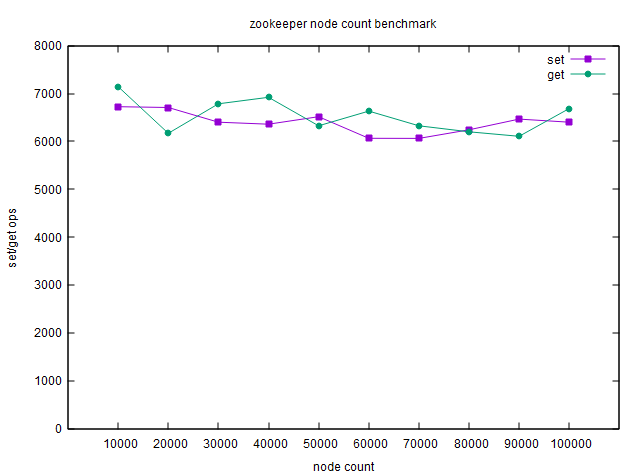
可见节点数的增加并不会对zookeeper读写性能造成影响。
节点数据大小对读写性能的影响
这个网上其实已经有公认的结论。本身单个节点数据越大,对网络方面的吞吐就会造成影响,所以其数据越大读写性能越低也在预料之中。
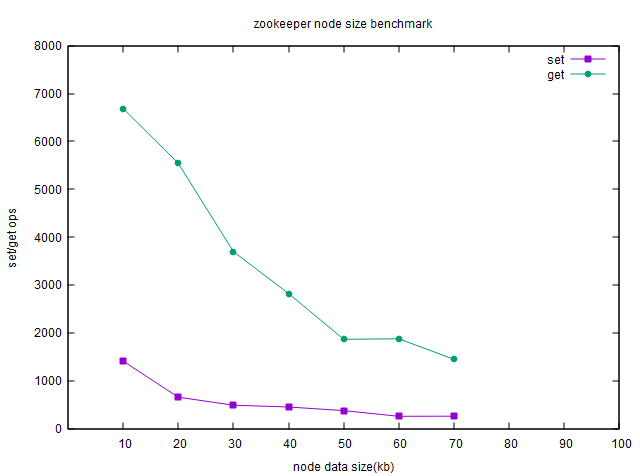
写数据会在zookeeper集群内进行同步,所以其速度整体会比读数据更慢。该实验需要把超时时间进行一定上调,同时我也把JVM最大堆大小调整到8G。
测试结果很明显,节点数据大小会严重影响zookeeper效率。
watch对读写性能的影响
zk-smoketest自带的latency测试有个参数--watch_multiple用来指定watch的数量,但其实仅是指定客户端的数量,在server端通过echo whcp | nc 127.0.0.1 4181会发现实际每个节点还是只有一个watch。
在我写的测试中,则是通过创建多个客户端来模拟单个节点上的多个watch。这也更符合实际应用。同时对节点的写也是在另一个独立的客户端中,这样可以避免zookeeper client的实现对测试带来的干扰。
每一次完整的测试,首先是对每个节点添加节点数据的watch,然后在另一个客户端中对这些节点进行数据改写,收集这些改写操作的耗时,以确定添加的watch对这些写操作带来了多大的影响。
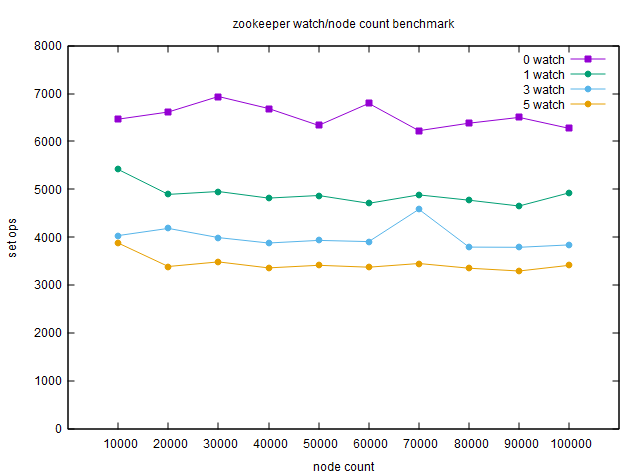
图中,0 watch表示没有对节点添加watch;1 watch表示有一个客户端对每个节点进行了watch;3 watch表示有其他3个客户端对每个节点进行了watch;依次类推。
可见,watch对写操作还是有较大影响的,毕竟需要进行网络传输。同样,这里也显示出整个zookeeper的watch数量同节点数量一样对整体性能没有影响。
总体结论
- 对单个节点的操作并不会因为zookeeper中节点的总数而受到影响
- 数据大小对zookeeper的性能有较大影响,性能和内存都会
- 单个节点上独立session的watch数对性能有一定影响